OCR Evaluation, Rebuilt for Insurance Claims in GenAI Era
Motivations
Processing unstructured scanned PDF documents has become non-trivial as more companies see the value of using GenAI/LLMs/RAG to unlock new insights and improve productivity. In the insurance domain, many historical documents are scanned and low quality. Digitizing them so they are usable for downstream LLM applications is increasingly challenging.
Traditional OCR mainly targets text reconstruction, and common metrics focus on character-level (CER) and word-level error rates (WER). Today, what we need is more layout-aware and semantically grounded understanding of documents. “Document Intelligence” may be a better term for the task.
We searched online for an established OCR/Document Intelligence evaluation framework. The closest benchmark we found is the OmniAI OCR Benchmark.
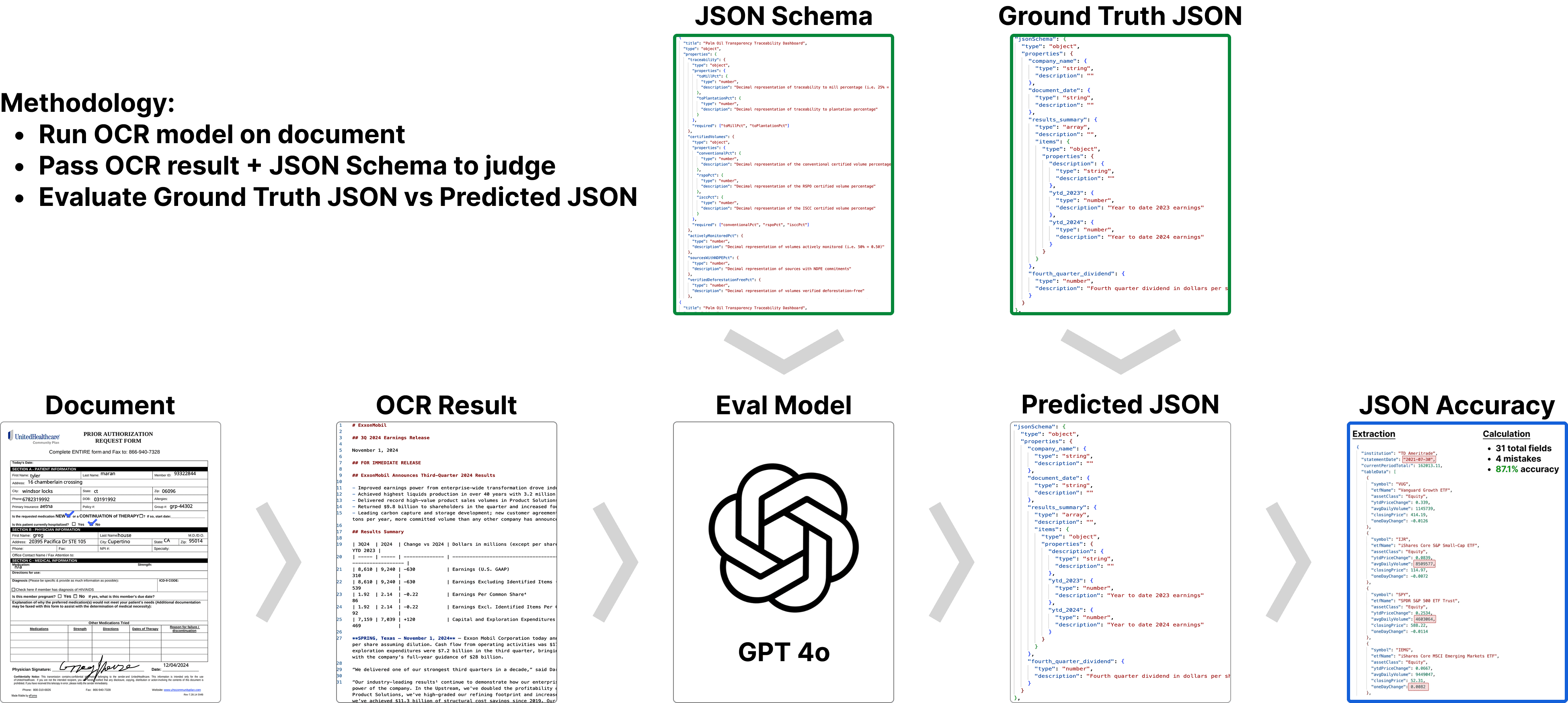
The best part of this framework is that it doesn’t evaluate the raw OCR output directly (which can be massive and hard to compare). Instead, it extracts structured information using a defined schema, making comparisons measurable. This approach has become practical now that LLMs are strong enough to generate JSON reliably.
However, we find the JSON accuracy metric too strict because it relies on exact-match comparisons of extracted values. This motivates us to enhance the framework to better fit our evaluation needs.
Our approach
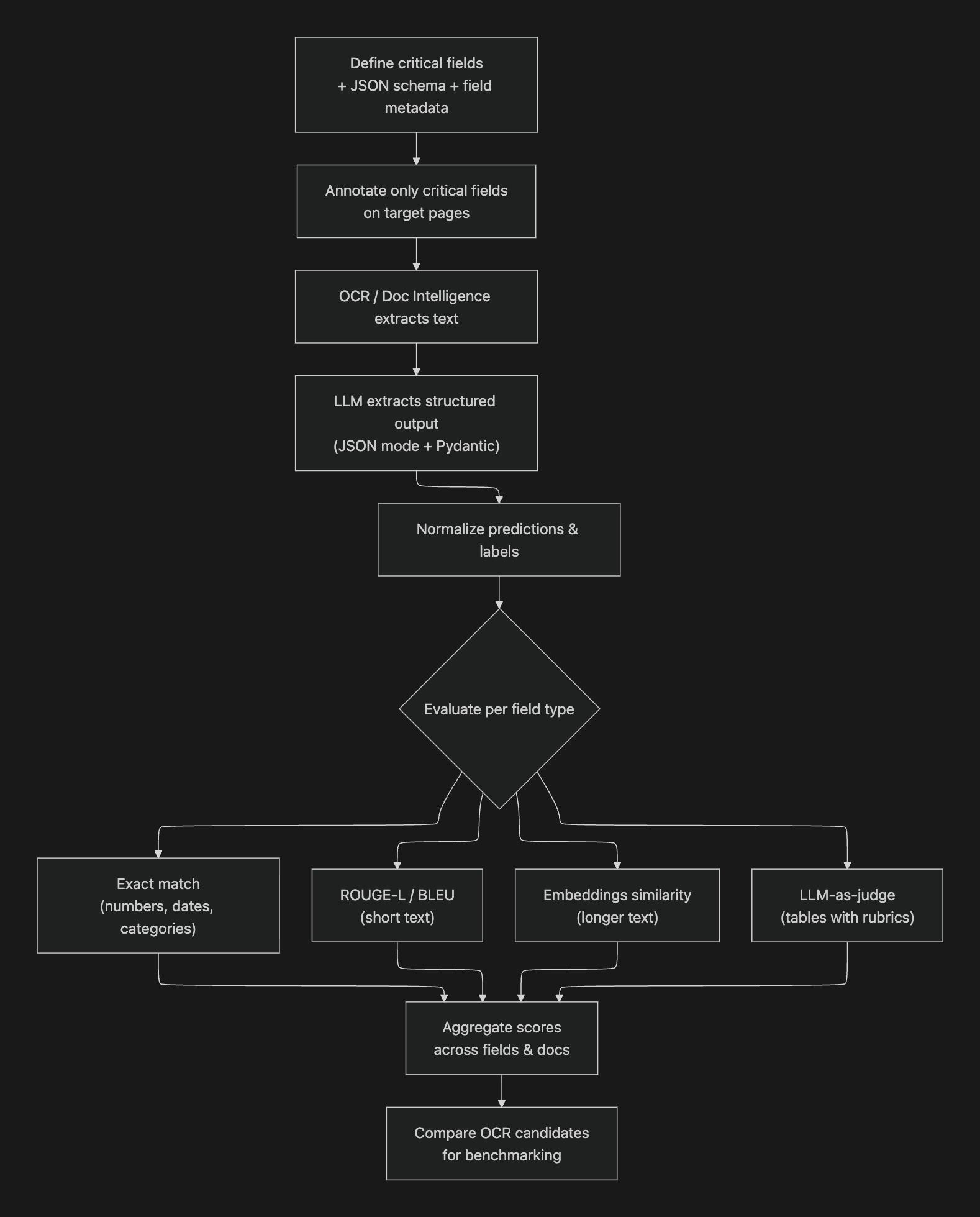
- Define the critical fields that matter and include them in a JSON schema. For each field, we also add metadata (e.g., checkbox, numeric, dates, handwriting, tables) to capture performance along different challenging dimensions.
- For pages of interest, annotate only the critical fields in the schema. This saves substantial effort compared to labeling everything.
- Convert the schema into a
pydanticmodel and use JSON mode to extract structured outputs from OCR’ed text. - When comparing predicted vs. annotated
JSON, apply basic text normalization and use a suite of metrics with increasing semantic tolerance:- Exact match (strict): best for numbers, dates, and categorical variables (e.g., gender, marital status)
- NLP overlap metrics: ROUGE-L and BLEU for short spans
- Semantic similarity: word/sentence embeddings for longer free-text fields
- LLM-as-a-judge with objective rubrics for tables
- Aggregate scores across fields and compare them across OCR candidates for benchmarking.
OCR eval in practice
We collected user feedback on OCR issues and grouped it into several broad categories.
Over two days, we annotated 600+ fields and used them as the basis for a preliminary OCR evaluation.
Here are a few observations from insurance claim documents:
- A mainstream document intelligence model (Azure Read prebuilt) significantly outperformed Tesseract (our open-source baseline).
- Traditional OCR performs well on printed text, numbers, and some handwriting, but still struggles with doctor’s handwriting, tables, complex layouts (e.g., form understanding), and certain checkmarks.
- Vision-language models (we tested MiniCPM-V-2.6) can hallucinate—especially for numbers and dates. On pages with dense or complex layouts, they also tend to stop mid-generation.
Other considerations
- Bounding boxes / polygons: preferable, since they enable visual grounding and downstream applications.
- Confidence scores: preferable, since they enable quality monitoring and human review workflows.
- Robustness, speed, and cost: traditional OCR is still the practical default.
- Output format: Markdown is often preferable to plain text because it preserves layout cues.
Final recommendations
A mainstream document intelligence model is usually enough to prototype quickly and cover ~80% of typical document-ingestion needs.
Vision-language models look attractive, but we don’t recommend them as a primary OCR solution—at least for our use case.
In practice, we want traditional OCR to provide:
- bounding boxes (for grounding)
- confidence scores (for QA and human-in-the-loop)
We also explored combining traditional OCR and VLMs to get the best of both worlds. Two promising approaches:
- Feed the page image and OCR’ed text/Markdown into a VLM, with prompts designed to correct foreseeable OCR issues.
- Use layout-aware OCR to segment the page, then route only low-confidence regions (bounding boxes/segments) to a VLM—balancing quality gains against VLM cost.
Leave a comment