Handling Long-Running Tasks in Modern Web Apps
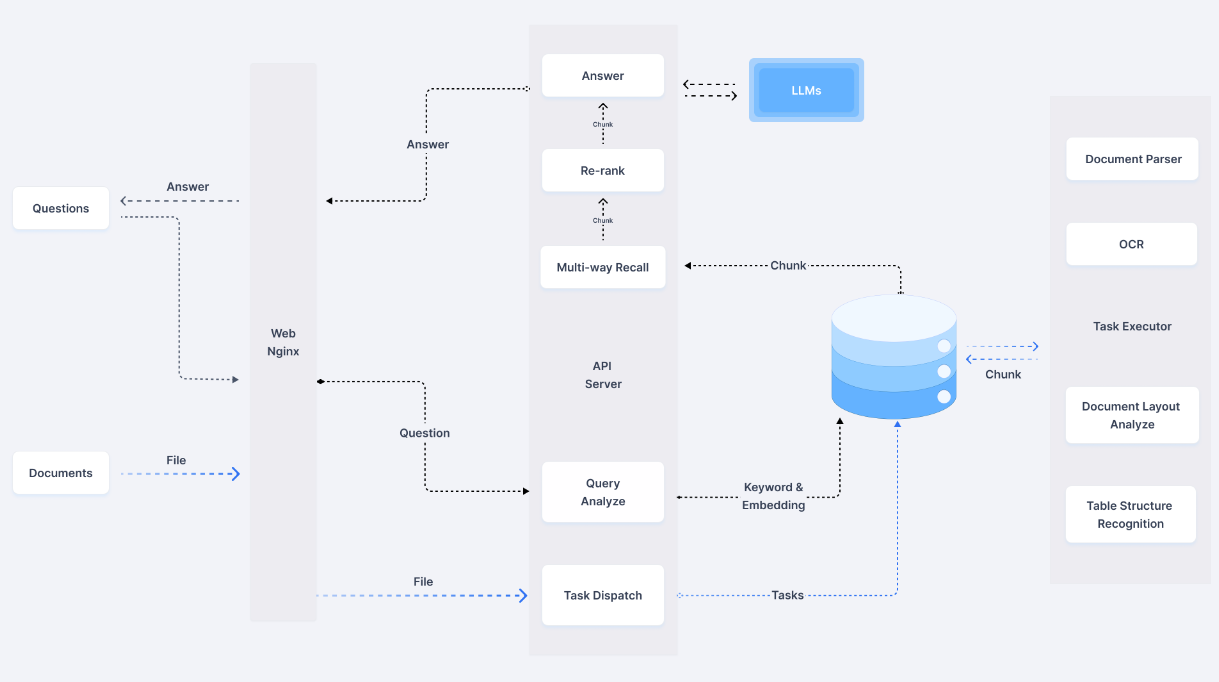
Have you ever wondered how some apps, like Airflow, efficiently track the progress of tasks that take a long time to complete? HTTP APIs, which typically handle communication between frontends and backends, can only sustain connections for a few minutes before timing out. This limitation became clear to me recently while exploring RAGflow, which also deals with long-running tasks such as OCR, chunking, question-answering, and keyword extraction. These processes can take several minutes to finish, yet RAGFlow manages to update task progress seamlessly for users.
Curious, I delved into RAGflow’s codebase and uncovered its approach. The backend server spawns multiple worker processes to handle the heavy lifting, while the server itself hosts an API layer that facilitates task submissions from the frontend. The workers send progress updates to Redis, a message broker, and the frontend periodically fetches task status updates from the server using APIs.
RAGFlow system architecture
A Mini App for Long-Running Jobs
HTTP POST methods alone are unsuitable for tasks with lengthy execution times. A better approach is to delegate such tasks to background processes and update the progress asynchronously. To illustrate this design, I built a simple demo using a FastAPI backend and a Vue 3 frontend, with Redis facilitating communication between the server and workers.
Tech Stack:
- Backend:
FastAPI - Frontend:
Vue - Messaging Broker:
Redis
Long task app demo
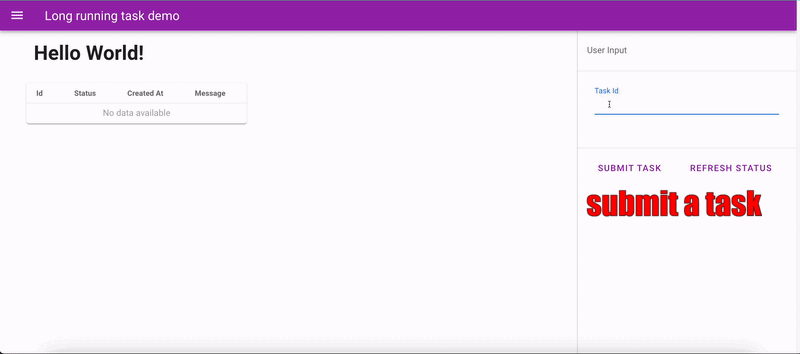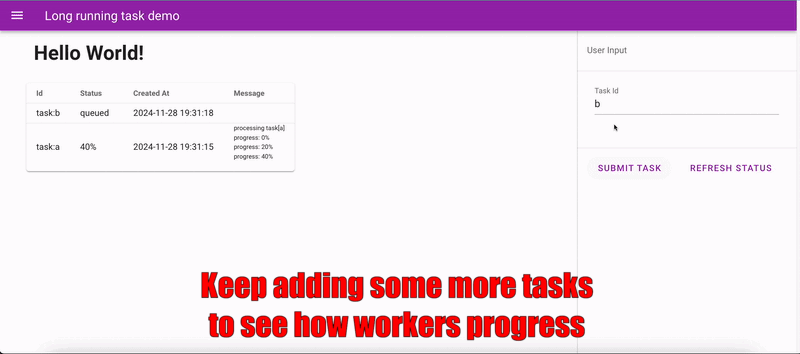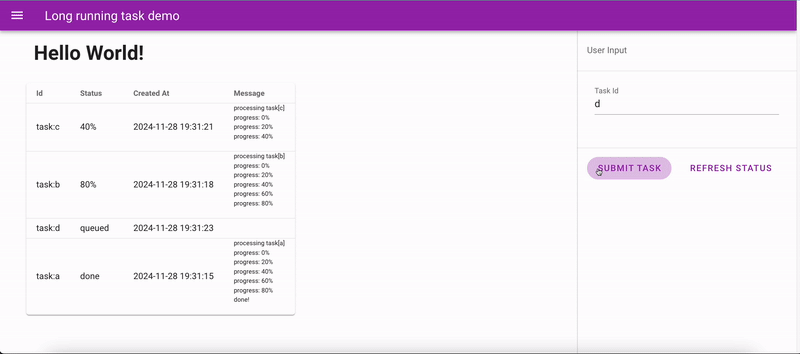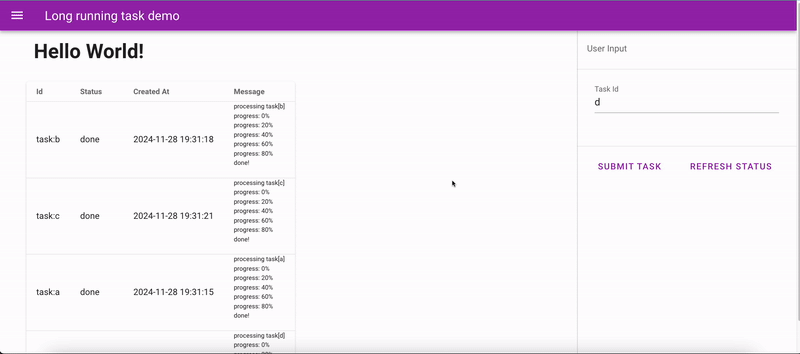
In this demo, two background workers are spawned alongside the server process. At most, two tasks can be processed simultaneously. The workers update the server with progress data, which the frontend fetches periodically via APIs
High-level Design
api.py: Orchestrates task submissions and communicates task progress between workers and the frontend through APIs.worker.py: Handles the actual task execution in separate worker processes.Redis: Acts as a message broker for passing tasks and progress updates between the server and workers.Frontend: Periodically fetches task progress from the server. While not the most efficient approach, this method is simple to implement
Worker Process Overview (worker.py)
In the worker process:
- The worker retrieves queued tasks from Redis using the rpop method. For simplicity, only task_id is passed in this demo, but in real-world scenarios, additional parameters can be included. To handle complex data, you can use json.dumps and json.loads to serialize and deserialize task details.
- The worker operates in an infinite loop, picking up tasks whenever they are available in the Redis queue.
- Progress updates are sent back to Redis using the hset method to update key-value data structures.
By designing apps with this approach, you can efficiently manage long-running tasks and provide real-time updates to end users without running into API timeout limitations.
import redis
# establish redis connection
r = redis.StrictRedis(host = "localhost", decode_responses=True)
# test the connection
ping = r.ping()
print(f"Redis Ping Result from worker: {ping}")
# a while loop to keep fetching new task in the queue
while True:
task_id = r.rpop('tasks') # get the task id from the queue
if task_id:
print(f'processing task[{task_id}]')
# simulate a long running job and report the progress to redis
for i in range(5):
r.hset(f'task:{task_id}', 'status', f'{i/5:.0%}') # save progress to status
time.sleep(1)
r.hset(f'task:{task_id}', 'status', 'done') # save progress to status
else:
print('no more tasks, waiting ...')
time.sleep(1)
Server Process Overview(api.py)
In the server process, there are a few key elements.
- a POST method
submit_taskfor task submission. It can be either single or multiple task sumbission. - a GET method
task_statusfor fetching latest task status. - a GET method
appto navigate the entrypoint of the webapp. - (optional) function to spawn worker process automatically from main process. The same can be achieved using a bash script.
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Task(BaseModel):
task_id: str
# define a post method for task submission
@app.post("/submit_task")
def submit_task(task: Task):
task_id = task.task_id
r.hset(f'task:{task_id}', 'status', 'queued') # set status to queued by default
r.lpush('tasks', task_id) # push the task to queue in redis
print(f'task[{task_id}] pushed to queue')
return {'status': 'ok'}
# define another get method to show all the task status
@app.get("/task_status")
def get_task_status():
tasks = []
for task in r.scan_iter('task:*'): # all the task defined are start with 'task:'
status = r.hget(task, 'status')
tasks.append({'task_id': task, 'status': status})
return{'tasks': tasks}
# define a get method as entypoint of the webapp
from fastapi.responses import FileResponse
@app.get("/app")
def read_index():
return FileResponse("./app.html")
# Run workers from api.py using subprocess
import subprocess
def run_worker():
python_path = sys.executable
subprocess.run([python_path, "worker.py"])
n_workers = 2
for _ in range(n_workers):
process = Process(target = run_worker)
process.start()
Frontend (app.html)
Built with Vue 3, the frontend includes:
- A
getTasksfunction to fetch task statuses. - A
setIntervalJavaScript function to automate periodic status updates.
// define a function a call API to fetch latet task status
getTasks: function () {
axios.get("task_status").then(
resp => resp.data.tasks
).then(
data => {
this.tasks = data
// console.log('fetch data')
}
)}
// ...
// use setInterval to perodically refetch the task status
setInterval(this.getTasks, 1000)
Quick start
For a detailed walkthrough, visit my GitHub repository.
Leave a comment