Build A Simple Machine Translator encoder-decoder framework with lstm
Introduction
seq2seq model is a general purpose sequence learning and generation model. It uses encoder decoder arthitecture, which is widely wised in different tasks in NLP, such as Machines Translation, Question Answering, Image Captioning.
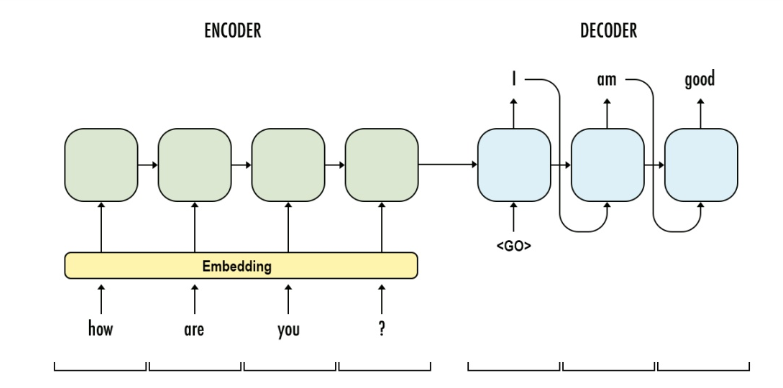
The model consists of two major components:
-
Encoder: a RNN network, used understand the input sequence and learning the pattern.
-
Decoder: a RNN netowrk, used to generate the sequence based on learned pattern from encoder.
steps to train a seq2seq model:
- Word/Sentence representation: this includes tokenize the input and output sentences, matrix representation of sentences, such as TF-IDF, bag-of-words.
- Word Embedding: lower dimensional representation of words. With a sizable corpus, embedding layers are highly recommended.
- Feed Encoder: input source tokens/embedded array into encoder RNN (I used LSTM in this post) and learn the hidden states
- Connect Encoder & Decoder: pass the hidden states to decoder RNN as the initial states
- Decoder Teacher Forcing: input the sentence to be translated to decoder RNN, and target is the sentences which is one word right-shifted. In the structure, the objective of each word in the decoder sentence is to predict the next word, with the condition of encoded sentence and prior decoded words. This kind of network training is called teacher forcing.
However, we can’t directly use the model for predicting, because we won’t know the decoded sentences when we use the model to translate. Therefore, we need another inference model to performance translation (sequence generation).
steps to infer a seq2seq model:
- Encoding: feed the processed source sentences into encoder to generate the hidden states
- Deocoding: the initial token to start is
<s>, with the hidden states pass from encoder, we can predict the next token. - Token Search:
- for each token prediction, we can choose the token with the most probability, this is called greedy search. We just get the best at current moment.
- alternatively, if we keep the n best candidate tokens, and search for a wider options, this is called beam search, n is the beam size.
- the stop criteria can be the
<e>token or the length of sentence is reached the maximal.
demo of english-chinese translation
Dataset
The data used in this post is from ManyThings.org. It provides toy datasets for many bilingual sentence pairs. I used english-chinese dataset.
clean punucations
- for english, I simply removed
,.!?and convert to lower case - for chinese, I only removed
,.!?。,!?\n
# raw data
0 Hi. 嗨。
1 Hi. 你好。
2 Run. 你用跑的。
3 Wait! 等等!
4 Hello! 你好
tokenize
- for english, I just split the sentence by space
- for chinese, I used jieba parser to cut the sentence.
def clean_eng(x):
x = x.lower()
x = re.sub('[,.!?]','',x)
return x
def clean_chn(x):
x = re.sub('[,.!?。,!?\n]','',x)
# use jieba parser to cut chinese
x = jieba.cut(x)
return ' '.join(x)
# processed data
0 hi 嗨
1 hi 你好
2 run 你 用 跑 的
3 wait 等等
4 hello 你好
sequence reprenstation
I used integer to represent the word in the sentence, so that we can use word embedding easily. Two separate corpus will be kept for source and target sentences. To cater for sentence with different length, we capped the sentence at maxlen for long sentence and pad 0 for short sentence.
I used below code snippet to generate vocabulary size, max_len, and padded sequence for both english and chinese sentences.
def tokenize(texts, maxlen = 20, num_words = 9000):
"""
tokenize array of texts to padded sequence
Parameters
----------
texts: list
list of strings
maxlen: int
max length of sentence
num_words: int
max vocab size
Returns
----------
tuple (tokenizer, vocab_size, max_len, padded_seqs)
"""
tokenizer = Tokenizer(filters='',num_words = num_words, oov_token = '<oov>')
tokenizer.fit_on_texts(texts)
vocab_size = len(tokenizer.index_word) + 1
max_len = max(list(map(lambda i: len(i.split()), texts)))
max_len = min(max_len, maxlen)
vocab_size = min(vocab_size, num_words)
seqs = tokenizer.texts_to_sequences(texts)
padded_seqs = pad_sequences(seqs, max_len, padding='post')
return tokenizer, vocab_size, max_len, padded_seqs
The resulting prepared data should look like something below:
# sequence representation
0 [928] [1012]
1 [928] [527]
2 [293] [7, 141, 200, 5]
3 [160] [1671]
4 [1211] [527]
# padded sequences
0 [ 928 0 0 0 0 0 0 0 0] [1012 0 0 0 0 0 0 0 0 0 0 0 0 0]
1 [ 928 0 0 0 0 0 0 0 0] [ 527 0 0 0 0 0 0 0 0 0 0 0 0 0]
2 [ 293 0 0 0 0 0 0 0 0] [ 7 141 200 5 0 0 0 0 0 0 0 0 0 0]
3 [ 160 0 0 0 0 0 0 0 0] [1671 0 0 0 0 0 0 0 0 0 0 0 0 0]
4 [1211 0 0 0 0 0 0 0 0] [ 527 0 0 0 0 0 0 0 0 0 0 0 0 0]
Model Configuration
we will need 3 models:
- an integrated encoder-decoder model for training
- an encoder model and a decoder model for inference
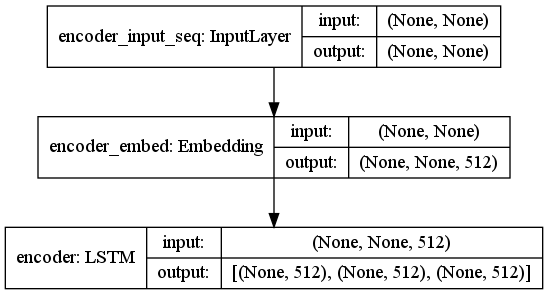
Encoder
Encoder is simply an Embedding layer + LSTM.
- input: the padded sequence for source sentence
- output: encoder hidden states
For simplicity, I used the same latent_dim for Embedding layer and LSTM, but they can be different.
LSTM need set return_state True, to output the hidden states (ht,ct). By fault, LSTM only output the output array (Ot) from the last time-step.
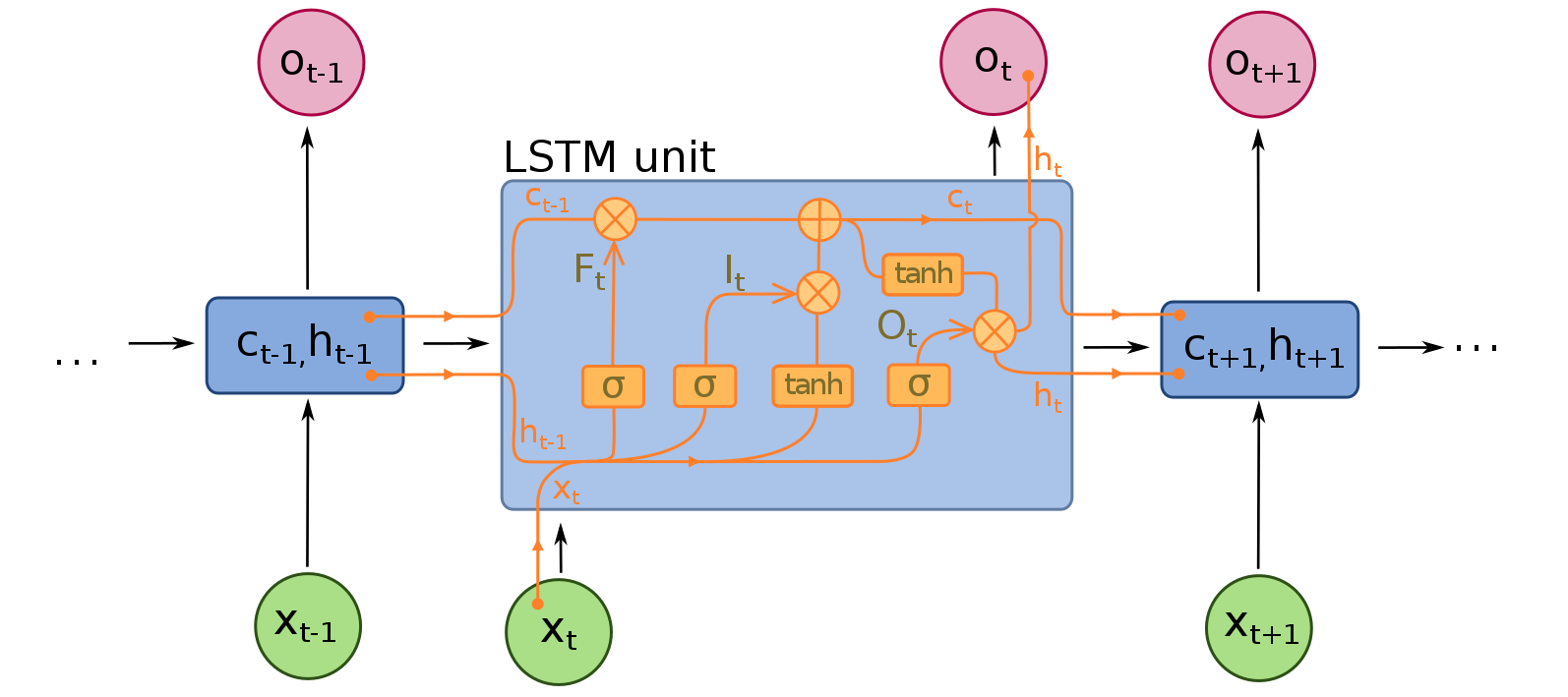 illustration of LSTM cell
illustration of LSTM cell
# encoder model
enc_input = Input((None,), name = 'encoder_input_seq')
# need add 1 space, because embedding look up table starts from 1
enc_embed = Embedding(src_vocab_size + 1, latent_dim, name = 'encoder_embed')
# set return_state True
encoder = LSTM(latent_dim, return_state=True, name = 'encoder')
enc_z, enc_state_h, enc_state_c = encoder(enc_embed(enc_input))
enc_states = [enc_state_h, enc_state_c]
enc_model = Model(enc_input, enc_states)
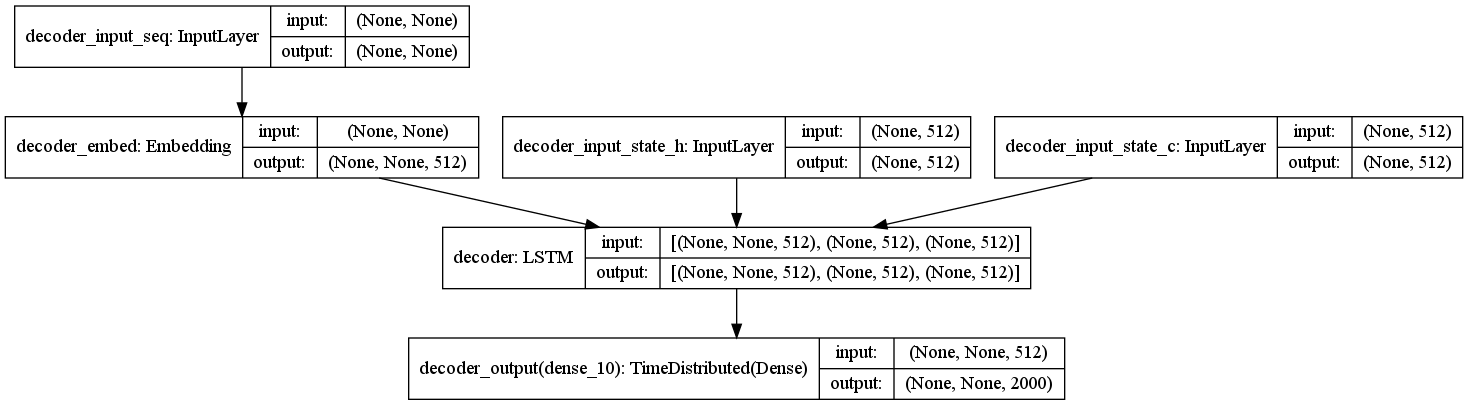
Decoder
Decoder is another combining of Embedding layer and LSTM.
- input: encoder hidden states and input decoded sequence
- output: the target decoded sequence (one word shifted)

# decoder model
dec_input = Input((None,), name = 'decoder_input_seq')
dec_state_h_input = Input((latent_dim,), name = 'decoder_input_state_h')
dec_state_c_input = Input((latent_dim,), name = 'decoder_input_state_c')
dec_states_input = [dec_state_h_input, dec_state_c_input]
dec_embed = Embedding(tar_vocab_size + 1, latent_dim, name = 'decoder_embed')
# set return sequence True, so that we can compare all the next words
decoder = LSTM(latent_dim, return_state=True, return_sequences=True, name = 'decoder')
# softmax layer to output the target tokens
dec_fc = TimeDistributed(Dense(tar_vocab_size, activation='softmax'), name = 'decoder_output')
dec_z, dec_state_h, dec_state_c = decoder(dec_embed(dec_input), initial_state = dec_states_input)
dec_states_output = [dec_state_h, dec_state_c]
dec_output = dec_fc(dec_z)
dec_model = Model([dec_input]+dec_states_input, [dec_output]+dec_states_output)
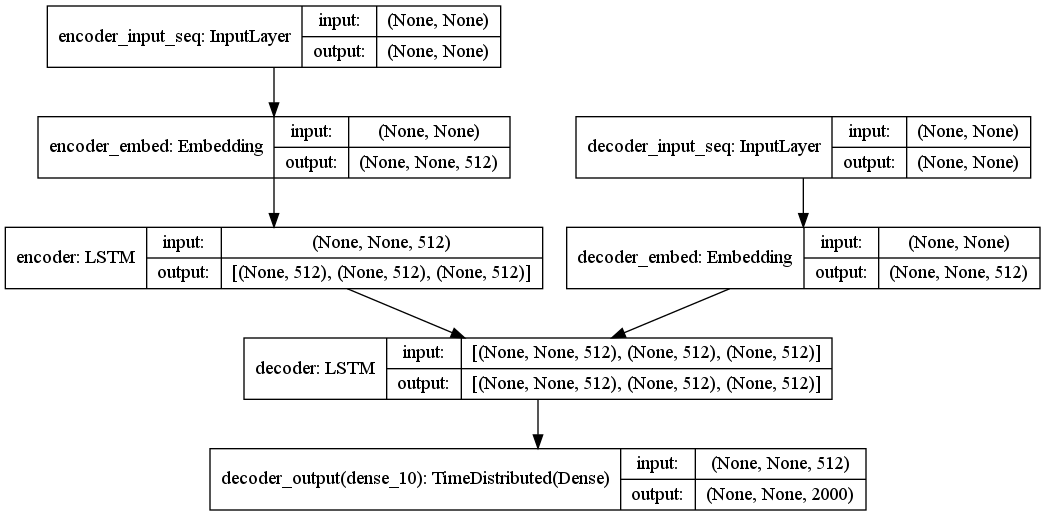
Encoder-Deocder
To train the encoder-decoder network, we just combine the parts together.
# decoder gets the inital states from encoder
tar_logit, _, _ = decoder(dec_embed(dec_input), initial_state= enc_states)
# project the target dimension for prediction
tar_output = dec_fc(tar_logit)
enc_dec_model = Model([enc_input, dec_input], tar_output)
enc_dec_model.compile(optimizer='adam', loss='categorical_crossentropy')
Model Training
As mentioned earlier, we will teach forcing for the sequence training. Before that, we need prepare the target sequence by shifting one word of decoder sequence.
src_tokenizer, src_vocab_size, src_max_len, encoder_input_seq = util.tokenize(data[:,0], max_len, max_vocab_size)
tar_tokenizer, tar_vocab_size, tar_max_len, decoder_input_seq = util.tokenize(data[:,1], max_len, max_vocab_size)
# target sequence take the shifted words
decoder_target_seq = decoder_input_seq[:,1:]
# remove the last word from original input sequence to align with target sequence
decoder_input_seq = decoder_input_seq[:,:-1]
#example
decoder_input_seq: [ 7 141 200 5 0 0 0 0 0 0 0 0 0 ]
decoder_target_seq: [ 141 200 5 0 0 0 0 0 0 0 0 0 0]
After preprocess, the model configuration I am using is:
- src_vocab_size’: 3603
- ‘src_max_len’: 9
- ‘tar_vocab_size’: 5000
- ‘tar_max_len’: 13
- ‘latent_dim’: 512
Define some callbacks to save model, early stop during our training.
checkpoint = ModelCheckpoint(filepath=weight_path,
save_best_only=True,
save_weights_only=True,
monitor='val_loss',
verbose = 2)
early_stop = EarlyStopping(monitor='val_loss',
patience=3)
callbacks = [checkpoint, early_stop]
Now, grab a cup of coffee and wait for the results.
enc_dec_model.fit([encoder_input_seq, decoder_input_seq], decoder_target_matrix,
batch_size=batch_size,
epochs=epochs,
shuffle = True,
callbacks=callbacks,
validation_split=0.1)
Train on 9000 samples, validate on 1000 samples
Epoch 1/30
8960/9000 [============================>.] - ETA: 0s - loss: 0.8042
Epoch 00001: val_loss improved from inf to 2.19257, saving model to ./weight/encoder_decoder_model_weights.h5
9000/9000 [==============================] - 41s 5ms/step - loss: 0.8046 - val_loss: 2.1926
Epoch 2/30
4608/9000 [==============>...............] - ETA: 18s - loss: 0.6771
Model Inference
You can directly apply inference model, or you can load from previously trained weights.
# load my trained model
enc_dec_model, enc_mode, dec_model = enc_dec_lstm(**model_config)
enc_dec_model.load_weights(weight_path)
initial states and token
The initial states is predicted results from encoder. That can be achieved by enc_model.predict(src_input_seq). The initial token is <s>, I keep track of a triple of (index, token, prediction probability) for each prediction, thus the triple for initial token is ([1],['<s>'],[1.0]). The following code snippet generate the initial states and token, with the given source sentence.
def _init_states(enc_model, src_sentence, tokenizers, src_max_len):
"""generate the states from encoder
Args:
enc_model
src_sentence
tokenizers: tuple (src_tokenizer, tar_tokenizer)
src_max_len
Return:
tuple (target_triple, initial_states)
"""
src_tokenizer, tar_tokenizer = tokenizers
src_index_word = src_tokenizer.index_word
src_word_index = src_tokenizer.word_index
tar_index_word = tar_tokenizer.index_word
tar_word_index = tar_tokenizer.word_index
tar_token = '<s>'
tar_index = tar_word_index.get(tar_token, None)
if tar_index == None:
print('start token <s> not found!')
src_input_seq = src_tokenizer.texts_to_sequences([src_sentence])
src_input_seq = pad_sequences(src_input_seq, maxlen=src_max_len, padding='post')
states = enc_model.predict(src_input_seq)
return ([tar_index], [tar_token], [1.0]), states
update states and token
So start from <s>, the decoder will be used to update the states and generate predicted next token. We will extract the most likely token and append behind <s>. We keep updating the tokens, until we reach <e> token or reach the max time-step in decoding sentences.
def _update_states(dec_model, tar_triple, states, tokenizers):
""" update the decoder states
Args:
dec_model
tar_triple: (target index[list], target_token[list], target_probability[list])
states:
params:
Return:
tuple (tar_triple, states)
"""
src_tokenizer, tar_tokenizer = tokenizers
src_index_word = src_tokenizer.index_word
src_word_index = src_tokenizer.word_index
tar_index_word = tar_tokenizer.index_word
tar_word_index = tar_tokenizer.word_index
tar_index, tar_token, tar_prob = tar_triple
# predict the token probability, and states
probs, state_h, state_c = dec_model.predict([[tar_index[-1]]] + states)
states_new = [state_h, state_c]
# update the triple
# greedy search: each time find the most likely token (last position in the sequence)
probs = probs[0,-1,:]
tar_index_new = np.argmax(probs)
tar_token_new = tar_index_word.get(tar_index_new, None)
tar_prob_new = probs[tar_index_new]
tar_triple_new = (
tar_index + [tar_index_new],
tar_token + [tar_token_new],
tar_prob + [tar_prob_new]
)
return tar_triple_new, states_new
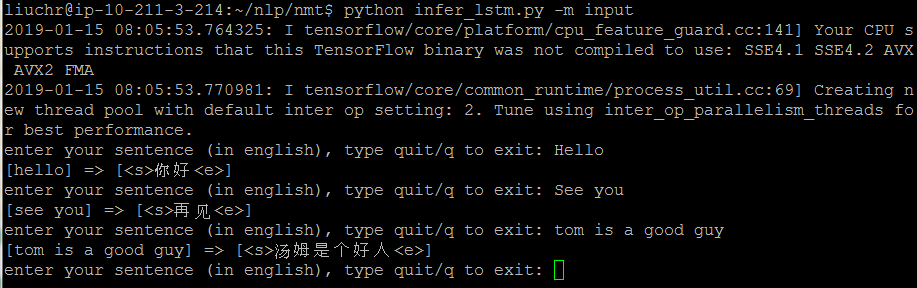
this is the code to generate translated results for the first 50 rows.
def infer_lstm(src_sentence, enc_model, dec_model, tokenizers, max_len = (9,13)):
src_max_len, tar_max_len = max_len
# initialize the triple and states
tr, ss = _init_states(enc_model, src_sentence, tokenizers, src_max_len)
for i in range(tar_max_len):
# update the triple and states
tr, ss = _update_states(dec_model, tr, ss, tokenizers)
if tr[1][-1] == '<e>' or tr[1][-1] == None:
break
return ''.join(tr[1])
import pandas as pd
df = pd.read_csv('./data/cmn_simplied.txt',sep='\t', header=None, names = ['en','cn'])
enc_dec_model.load_weights(weight_path)
for i in range(50):
src_raw = df.en.values[i]
src = clean_eng(src_raw)
dec = infer_lstm(src, enc_model, dec_model, tokenizers)
print('[%s] => [%s]'%(src,dec))
The results is not perfect, but some of them are quite funny.
[hi] => [<s>走开<e>]
[hi] => [<s>走开<e>]
[run] => [<s>小心脚下<e>]
[wait] => [<s>继续看<e>]
[hello] => [<s>你好<e>]
[i try] => [<s>我累死了<e>]
[i won] => [<s>我生病了<e>]
[oh no] => [<s>没有水<e>]
[cheers] => [<s>当然<e>]
[he ran] => [<s>他跑了<e>]
[hop in] => [<s>当然<e>]
[i lost] => [<s>我累死了<e>]
[i quit] => [<s>我累死了<e>]
[i'm ok] => [<s>我很快乐<e>]
[listen] => [<s>继续好<e>]
[no way] => [<s>没有问题<e>]
[no way] => [<s>没有问题<e>]
[really] => [<s>真可能<e>]
[try it] => [<s>保持安静<e>]
[we try] => [<s>我们开始吧<e>]
[why me] => [<s>告诉我他的事<e>]
[ask tom] => [<s>请汤姆走<e>]
[be calm] => [<s>保持安静<e>]
[be fair] => [<s>没有问题<e>]
[be kind] => [<s>没有问题<e>]
[be nice] => [<s>小心扒手<e>]
[call me] => [<s>让我走<e>]
[call us] => [<s>叫汤姆<e>]
[come in] => [<s>保持安静<e>]
[get tom] => [<s>汤姆会走<e>]
[get out] => [<s>保持安静<e>]
[go away] => [<s>走开<e>]
[go away] => [<s>走开<e>]
[go away] => [<s>走开<e>]
[goodbye] => [<s>再见<e>]
[goodbye] => [<s>再见<e>]
[hang on] => [<s>继续看<e>]
[he came] => [<s>他跑了<e>]
[he runs] => [<s>他很强壮<e>]
[help me] => [<s>帮我<e>]
[hold on] => [<s>抓住了<e>]
[hug tom] => [<s>汤姆快<e>]
[i agree] => [<s>我累死了<e>]
[i'm ill] => [<s>我生病了<e>]
[i'm old] => [<s>我是17岁<e>]
[it's ok] => [<s>它会发生<e>]
[it's me] => [<s>我很快乐<e>]
[join us] => [<s>我们开始吧<e>]
[keep it] => [<s>保持安静<e>]
[kiss me] => [<s>对不起<e>]
Extension
The full python code is available at Github: link
With this simple model setup, we still a lot of opportunities to improve, such as
- Richer Feature Encoding of sentence (POS Tagging, NER)
- Bidirectional-LSTM
- Stack more layers of LSTM
- Attention Mechansim
- Transformer Model
- Beam Search to improve the inference part
Leave a comment